Matrix Multiplication
Contents
Implementation

Default Synthesis
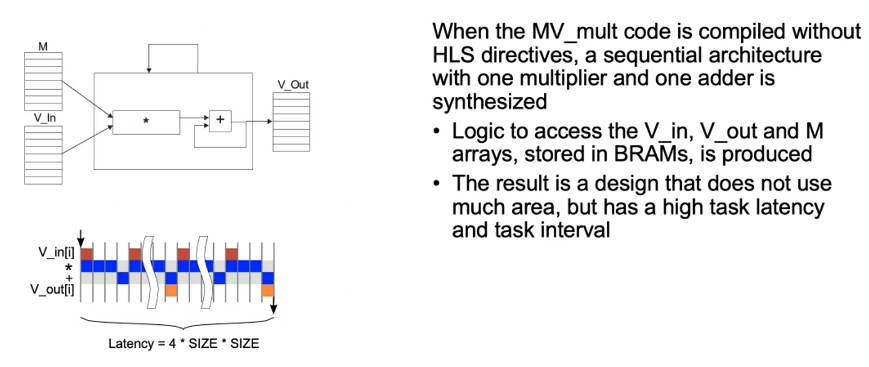
- Sequential architecture
- One multiplier
- One adder
- BRAM
- High task latency and task interval
Unrolling the inner loop (dot product loop)
Could also use the UNROLL directive, but for manual sake ...

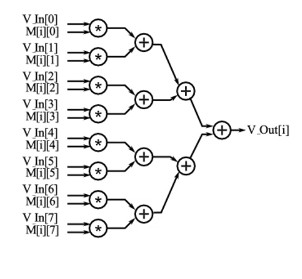
Sequential implementation of the unrolled inner loop

- Could do multiplication in several stages, and therefore start adding in advanced
- Note: A mux would be needed, and requires 1 LUT per bit
Pipelined execution of the inner loop
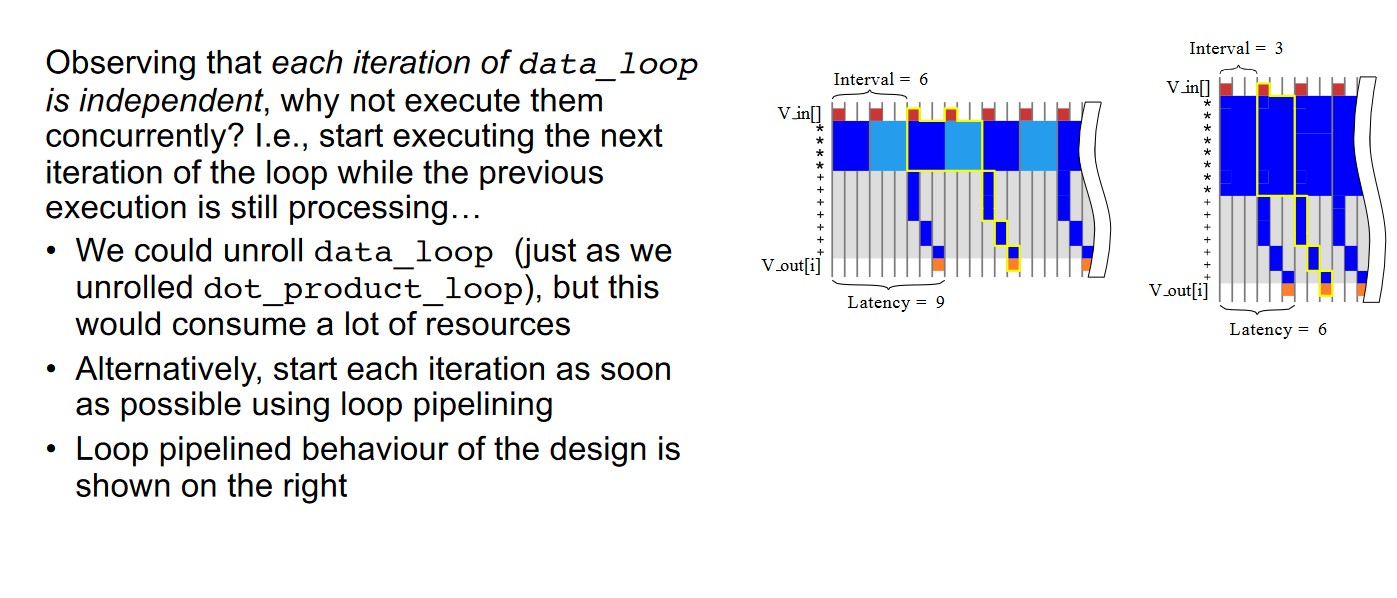
Task latency -> 3*size + 3
Pipelined Operators (i.e. Multipliers)
Note: A bunch of different things within the FPGA are already pipelined

Task Latency -> 3*size + 5
Note: Higher latency, but less multipliers
With Complete Array Partitioning
Task Latency -> size + 5
Note: Very high resource count
With Dual-Port RAM and Array Partitioning f=2
For instances where there are only two accesses, we could get away with using a dual-port ram and not need to partition the array completely.
If we are using a partitioning factor of f=2, we only have at most 2^f = 2^2 = 4 IOs (assuming using dual-port), provided we keep
II=1Larger factors would require muxes and incur an increased
II