Approximate Multipliers
Contents
Review of Addition Arithmetic In Computers
e.g. Binary addition of two single bits
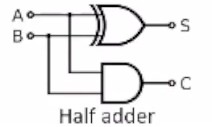
We can use a half adder circuit
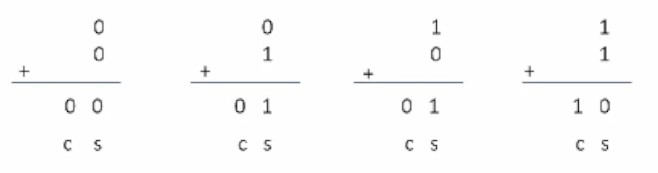
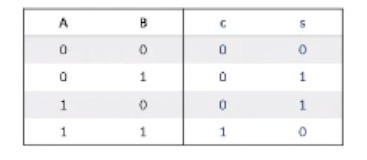
e.g. Binary addition of three single bits
Full adder circuit
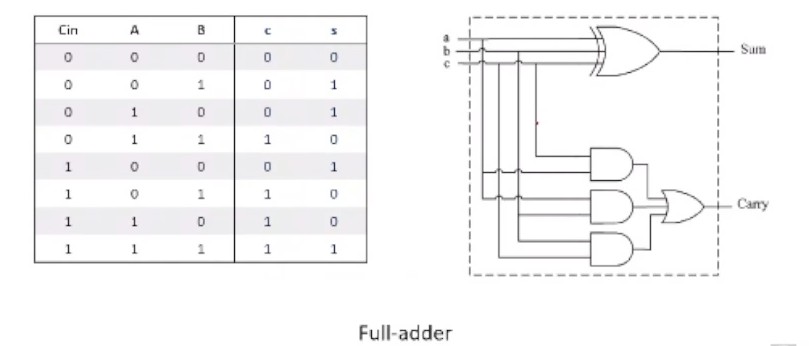
e.g. Addition of N-bit numbers
We can chain full-adder circuits together
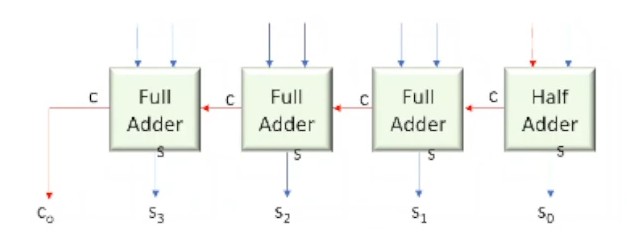
- Logic Area = (N-1) FA + 1 HA
- Delay: Delay of (N-1) FA + Delay of HA
Potential Issues
Logic Area (Space, Power)
Number of gates/logic elements.
In an FPGA, logic elements are our configurable logic blocks (CLBs) such as the Lookup Tables (LUTs)
Speed
i.e critical path delay
Optimised Designs
Carry Look-Ahead Adder
Improves the critical path, but requires a larger logic area
Bit Serial Adder
Smaller area and critical path, but requires multiple cycles
The input comes in one bit per cycle
Review of Multiplication Arithmetic in Computers
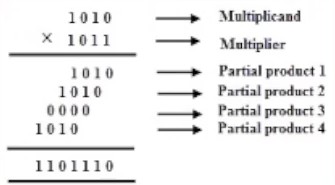
With binary multiplication, since the unit values can only be 0 or 1, multiplication is simply just an AND operation
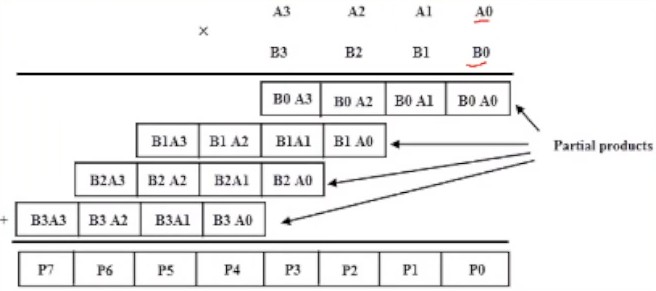
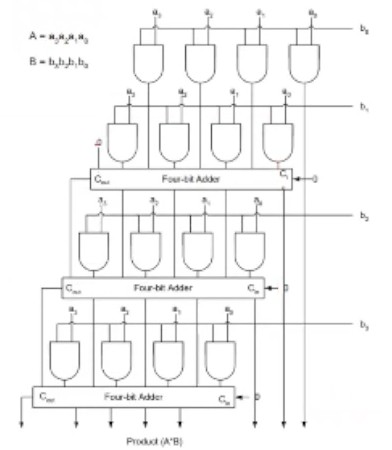
This multiplication just becomes a combination of AND and n-bit adder circuits.
- Logic Area Complexity - O(N^2)
- Delay Complexity - O(N^2)
Optimisations
- Wallace Tree Reduction
- Dadda Tree Reduction
Approximate Multipliers
There are different variations of adder and multiplier circuits, each which use have different logic area and delay complexities.
The previous example circuits can be classified as "exact circuits" - where their produced output is exactly the result of the input operation.
However sometimes we do not particularly need an exact output (would be ideal though). We can instead implement an approximate multiplier, which can possibly decrease the circuit complexity.
Aside | Error Resiliency - Some algorithms are inherently error resilient, and are often used to treat or suppress noisy input - mitigating the effect of errors on the output result
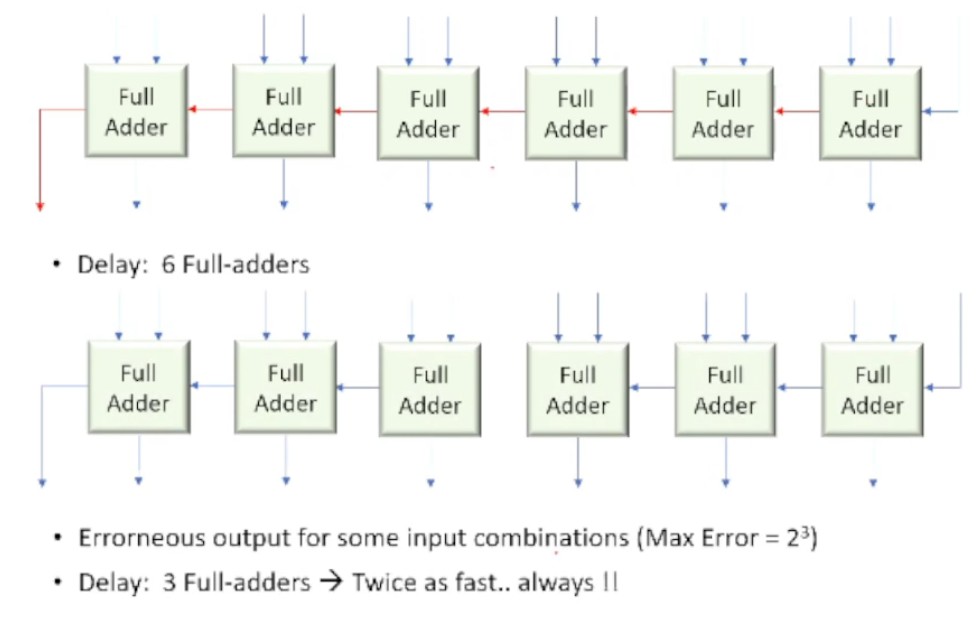
Example (Approximate Adder)
Consider the case of a 6-bit adder circuit where the lower 3 bits were disconnected.
An error would be introduced if the last 3 bits had any data, however for any addition of two values > 2^3, there would be no error.
This approximation change halves the required time to compute.
For additions of large numbers, the lower bits are not very significant (i.e. LSB) and do not dramatically affect the output
Approximate Log-based Multipliers
Recall that
log(AB) = log A + log BSo,
AB = antilog(log A + log B)
There are approximate log and antilog functions which help to simplify the computation
Mitchell's Algorithm (MA)
- Find the approximate log of inputs
K.XXX...
Where
K- Position of the leading 1 (as binary)XXX...the rest of the bits
Then, log(A) = K + X
- Add the two logs
- Extract the fractional bits and prepend a
1bit (to the whole number)- Scale -> Move the decimal
nplaces to the right (wherenis the result's whole numberKa + Kb
e.g 0.00010 becomes 1.00010
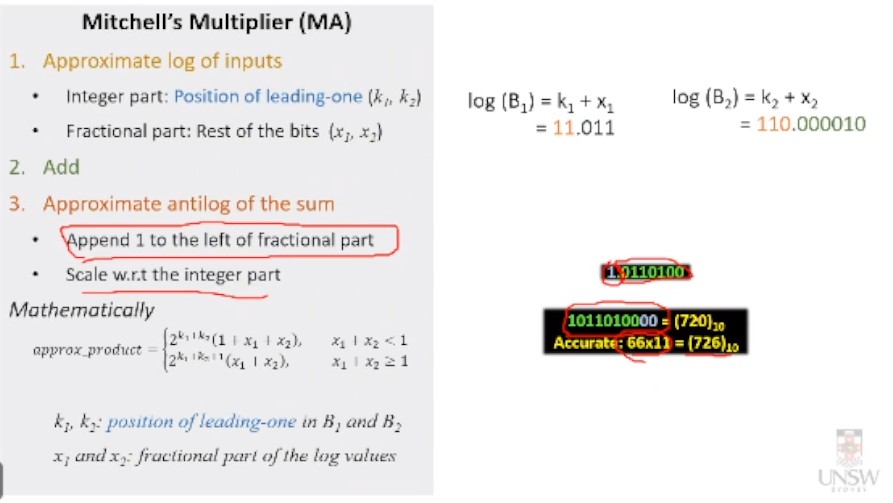
^ When x1 + x2 >= 1, we add 1 to the sum of k
Brain Dump: Approximately multiplying two numbers involves adding their MSB positions
Yeah, makes sense.
Example
Input = 11 x 66
11 (dec) = 1011 (bin)
66 (dec) = 1000010 (bin)
Step 1
1011 -> 11.011 (First 1 is in position 3 (bin = 11))
1000010 -> 110.000010 (First 1 is in position 6 (bin = 110))
Step 2
11.011 + 110.000010
= 1001.011010
Step 3
frac -> 0.011010
prepend 1 -> 1.011010
scale by 1001 (dec = 9) -> 1011010000
**Result
**1011010000 = 620
11 x 66 = 726
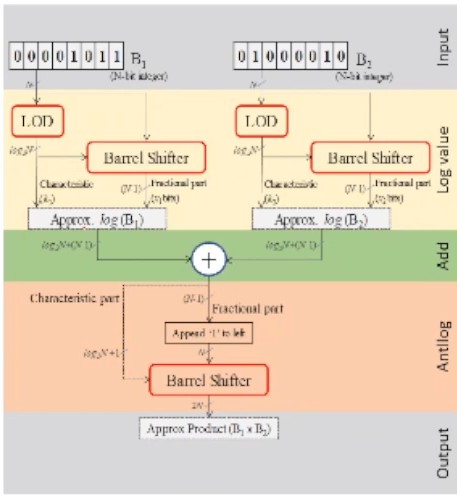
- LOD - Leading One Detector - Finds the position of the leading one
- Barrel Shifter - Shift by N bits
Error Calculation
Absolute Error
E = P - P_
abs(E)
Relative Error
RE = E/P*100%
Error in Mitchell's Algorithm

If either integer is an exact power of two, there is zero error.
Otherwise, looking at different profiles of our 3D error graph...
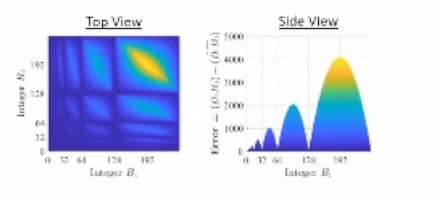
- The profile is replicated in every power-of-two (pair of k1 and k2)
- The error profile is scaled by 2^(k1+k2)
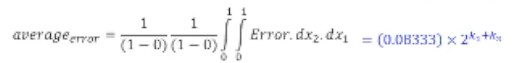
We can add this average error into our approximate product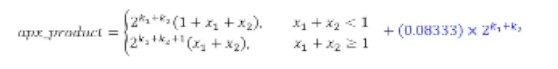
Can approximate 0.08333 ~= 0.078125 = 2^-4 + 2^-6

^ When x1 + x2 >= 1, we scale the average error down by half
REALM (Reduced-Error Approximate Log-Based Integer Multiplier) For an even better error correction, instead of using a mean average correction - we could calculate the error for each region, and then use a lookup table to find the correct error.-