Pipelined Processors
Contents
Pipelining involves performing several tasks at relatively the same time.
Since a multi-cycle processor instruction has its tasks split into stages, previous stages of the current instruction can be used by other instructions; in order to speed up execution.
i.e. a task uses stages A, B, C, D. When the task is on stage B, another task can use the resources in stage A
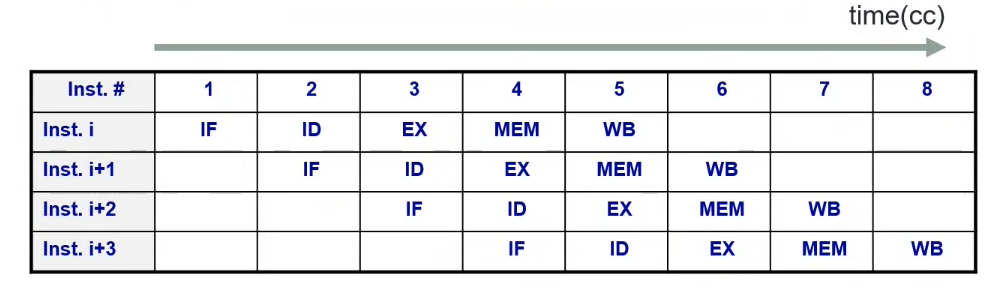
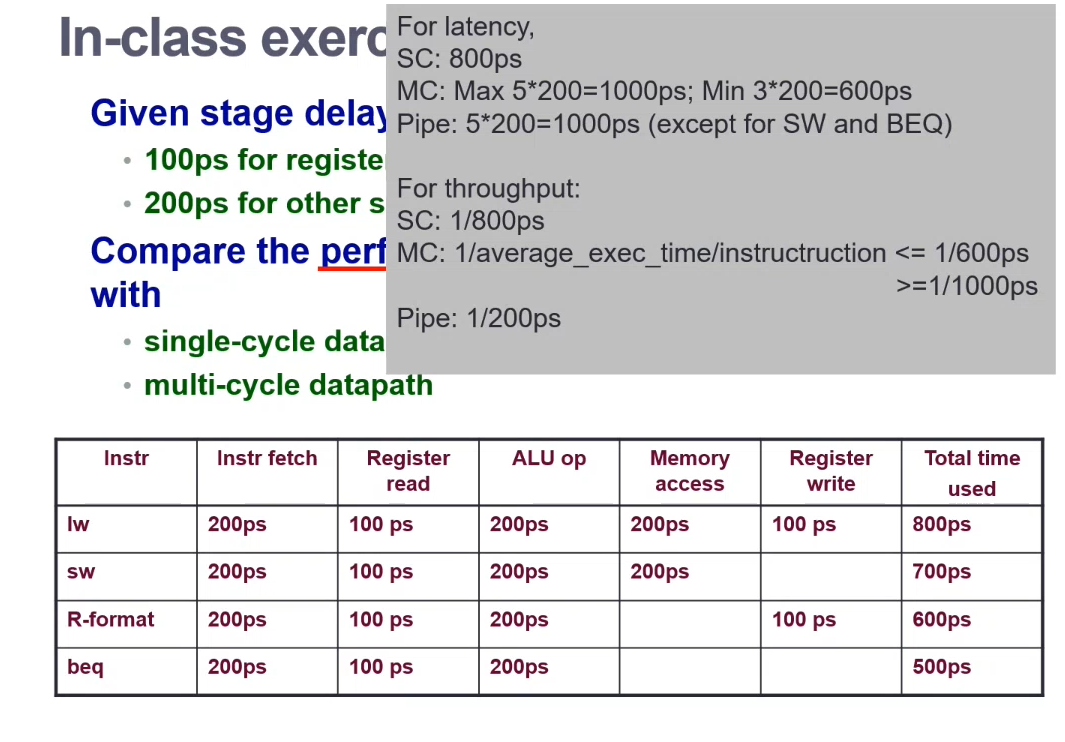
Compared to the example in multicycle processors, a pipelined design can execute the instructions in 8 clock cycles
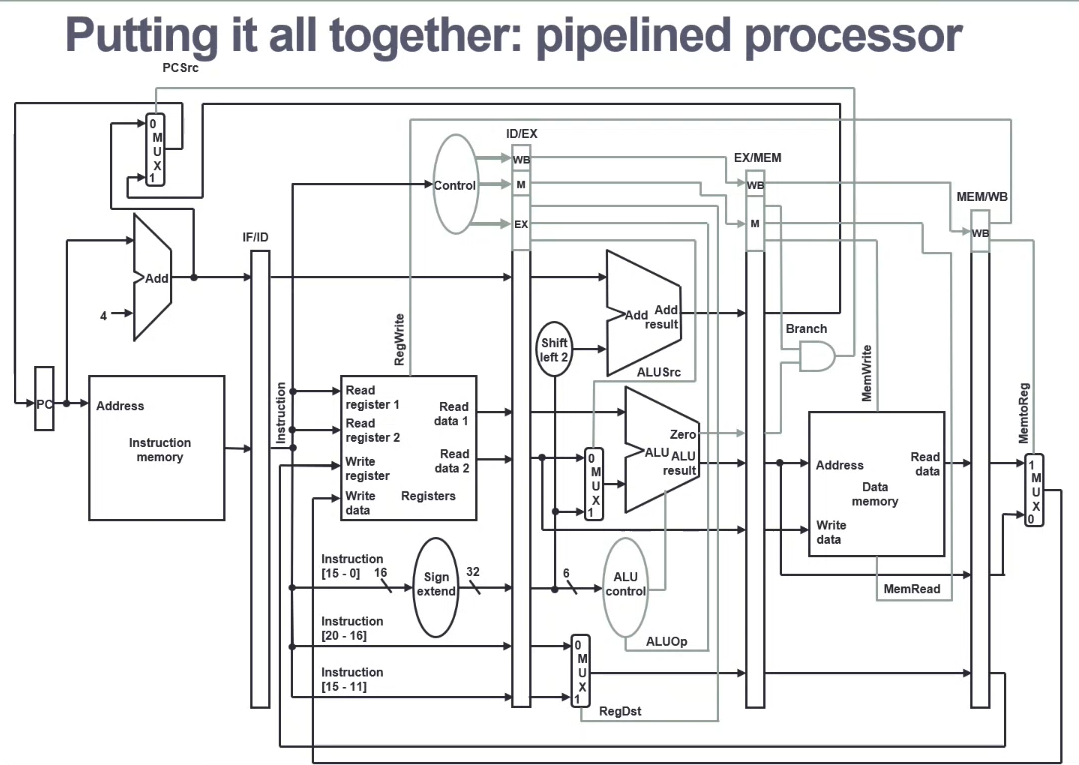
MIPS Pipelined Datapath
Stages
- IF - Instruction Fetch from memory
- ID - Instruction Decode and register read
- EX - EXecute operation or calculate address
- MEM - access MEMory operand
- WB - Write result Back to register
MIPS Design
- All instructions are 32-bits - easy to fetch in one cycle
- Few and regular instruction formats - can decode and read all in one step
- Load/store addressing - Can calculate the address in the ALU at an early stage, allowing access in a later stage
- Alignment of memory operands - allows memory access to take "one cycle"
- Most resources are available
Partitioning
Partition the single cycle datapath into sections - each section forms a stage.
- Try to balance the stages for similar stage delays (reduce clock cycle time)
- Try to make data flow in the same directions (avoid pipeline hazards)
- Make sure the correct data is used for each instruction
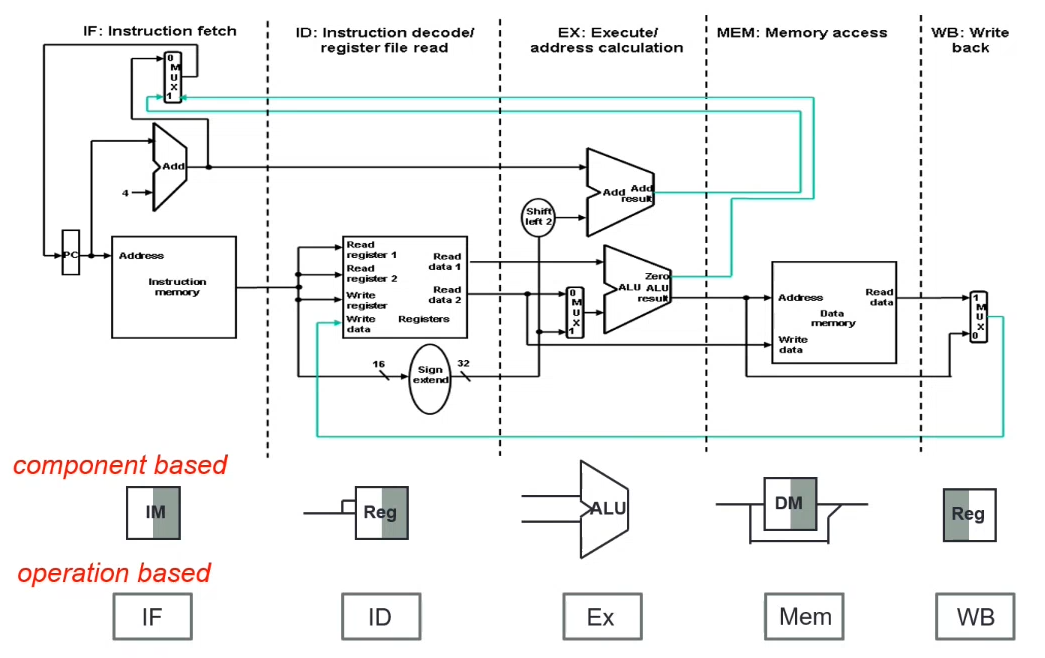
- Shaded|Unshaded - Write into
- Unshaded|Shaded - Read from
Find the shaded part of the component, that's the data direction
Pipeline Registers
To retain the values of an instruction to be used in other stages, the values are saved in pipeline registers. They are named by combining the two stages using that register.
e.g. IF/ID register
Each logical component (i.e. instruction memory, register read ports can only be used in a single pipeline stage.
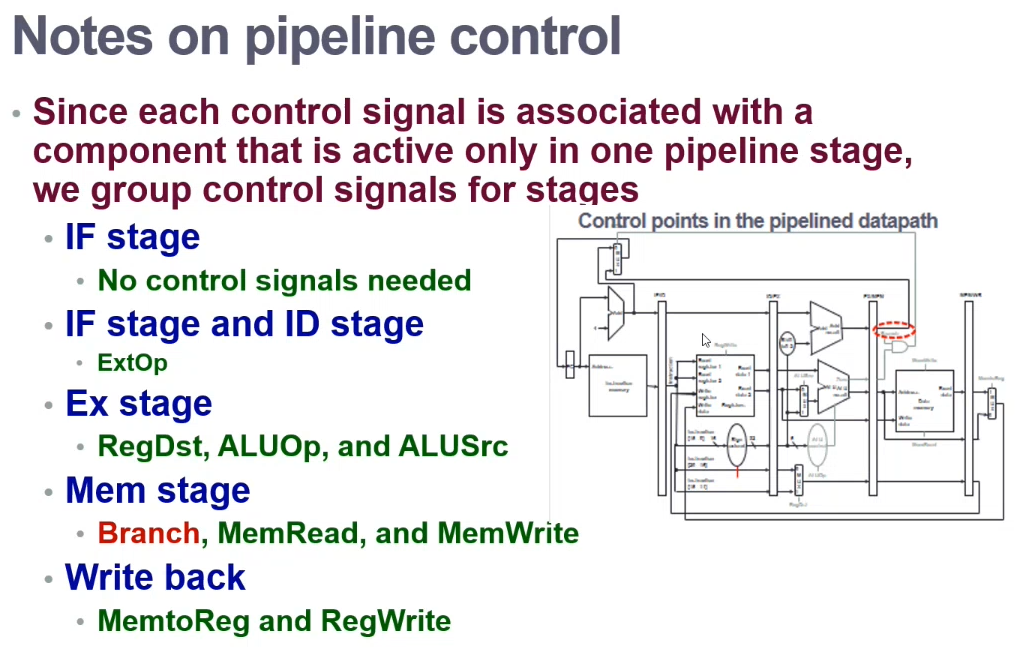
Pipeline Control
Pipeline processes need to be controlled
- Label control points
- Determine control settings
- Design control logic

Hazards
Situations where the instruction execution cannot proceed in the pipeline
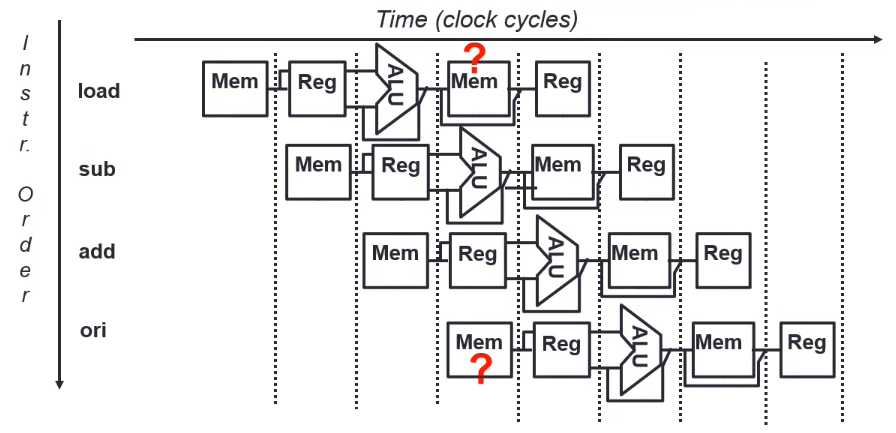
Structural Hazard
The required resource is busy
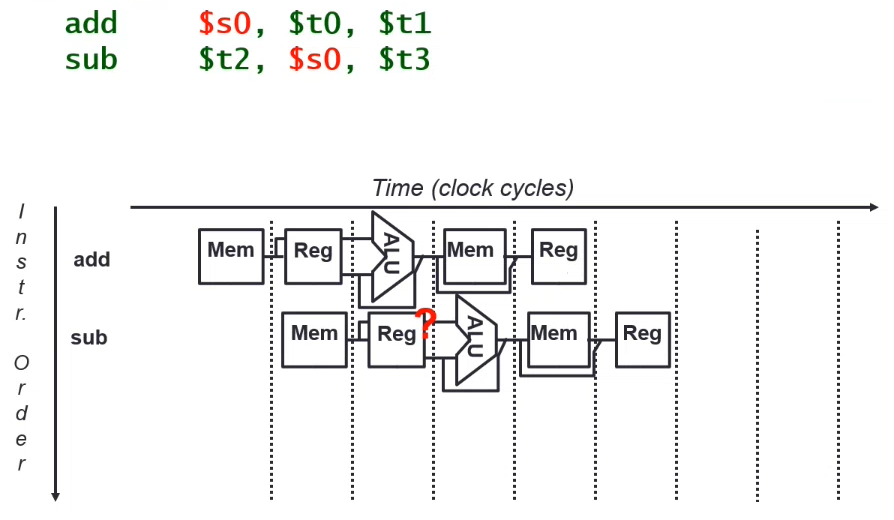
Data Hazard
Need to wait for the previous instruction to update its data
Data Dependency types
- RAR - Read after Read
- WAW - Write after Write
- WAR - Write after Read
- RAW - Read after Write
Control Hazard
The control decision cannot be made until the condition check by the previous instruction is completed
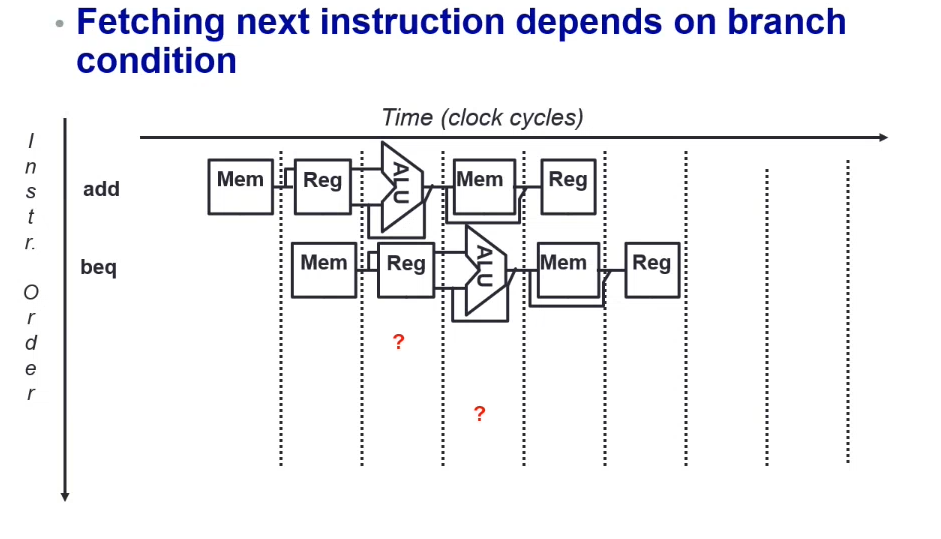
Mitigating Hazards
Mitigating Structural Hazards
Never access a resource more than once per cycle
- Allocate each resource to a single pipeline stage
- Duplicate resources if necessary (e.g. IMEM, DMEM)
- Every instruction must follow the same sequence of cycles/stages
- Skipping a stage can introduce structural hazards
- However, some trailing cycles/stages can be dropped
- i.e.
BRA/JMP- don't need WB or MEM
- i.e.

In an ideal case, CPI = 1 (given a constant stream of instructions, each cycle a new instruction starts, but another instruction finishes)
In a one-memory case, the CPI increases to 1.2 as DM and IM stages can't occur concurrently
Mitigating Data Hazards
Properly schedule / partition tasks in the pipeline
To detect data hazards, we check for data dependencies between instructions and its preceding instructions
- Eliminate WAR (write after read) by always fetching operands early in the pipeline
- ID stage
- Eliminate WAW (write after write) by doing all WBs in order
- Single stage for writing
Mitigating RAW (read after write)
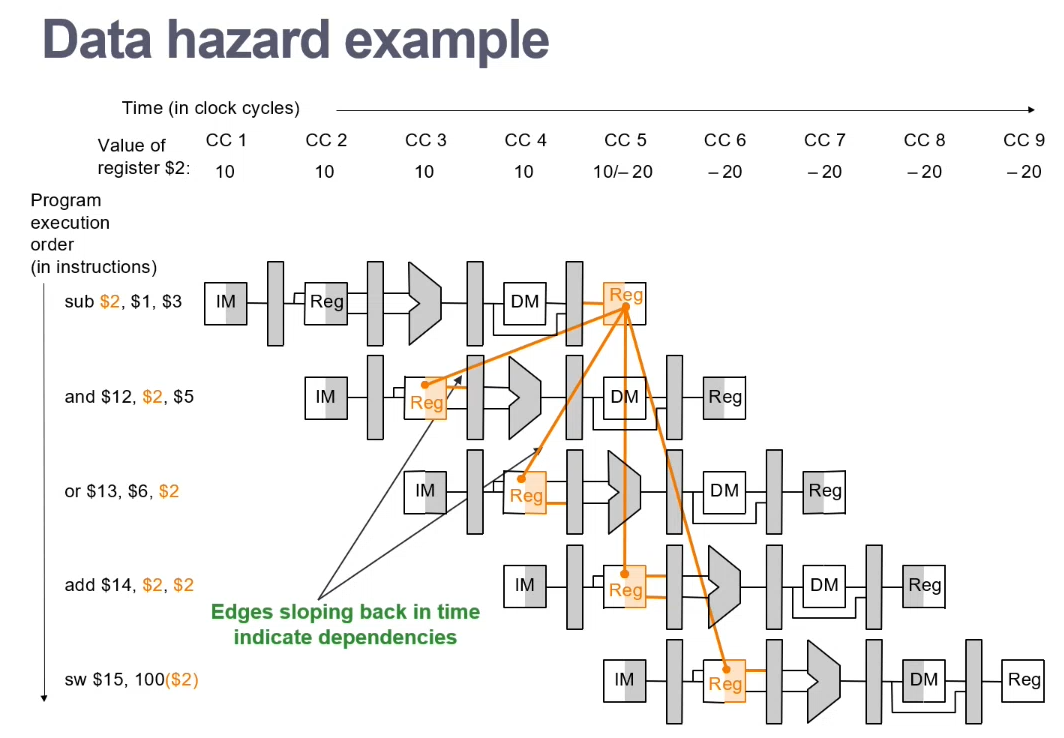
If instructions depend on the result of a previous instruction, we need to delay that instruction from occurring...
Stalling - stall the instruction execution
Load Use Hazard (LUH) - When a load instruction is followed by an instruction dependent on the memory data (i.e. "not yet")
Prevent PC and IF/ID registers from changing
Set the EX, MEM and WB control fields of the ID/EX register to 0 to perform a no-op
This is performed by a Hazard Detection Unit, which reads the states of the different pipeline registers, and controls the writeability of the IF/ID register
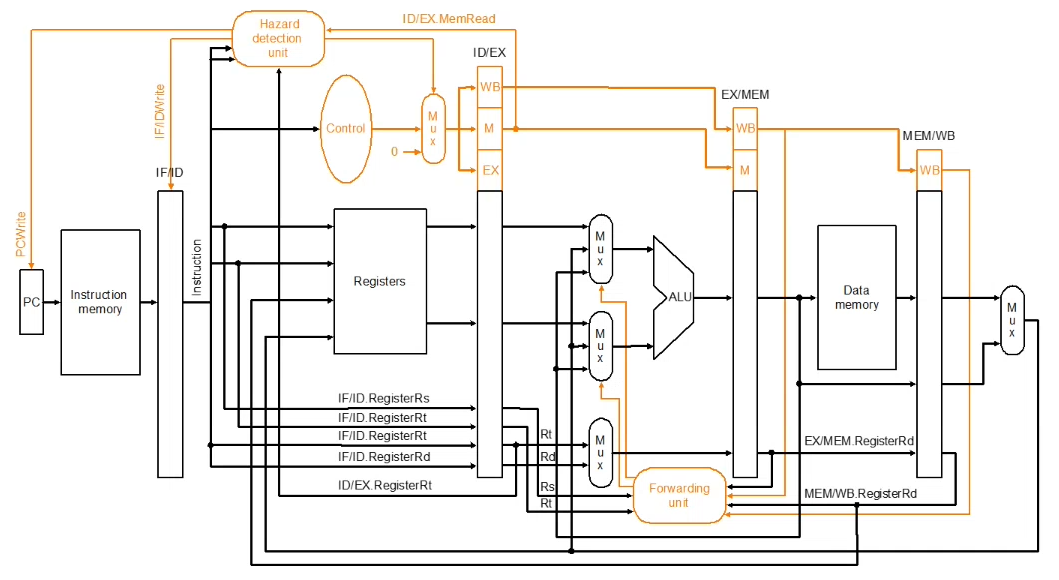
Forwarding - if the correct data is available, forward the data to where it is required
Update a pipeline register to contain the correct value, so that it can be used

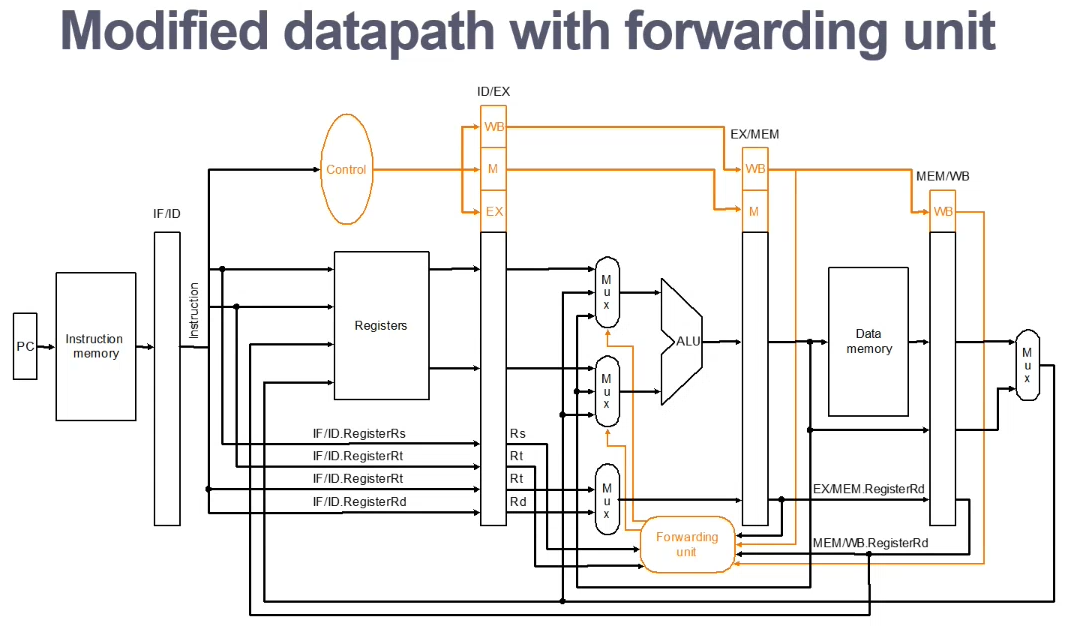
Stall AND Forward
Ooooh smart!
Static Predictions
Predicts that all branch instructions have the same behaviour - either never, or always taken
- When the prediction (never taken[?]) is correct, the pipeline continues processing
- When the prediction is wrong, the instruction(s?) after the branch instruction are discarded
Load each instruction every clock cycle, but discard the latter instructions if a branch occurs
Pipeline Flush
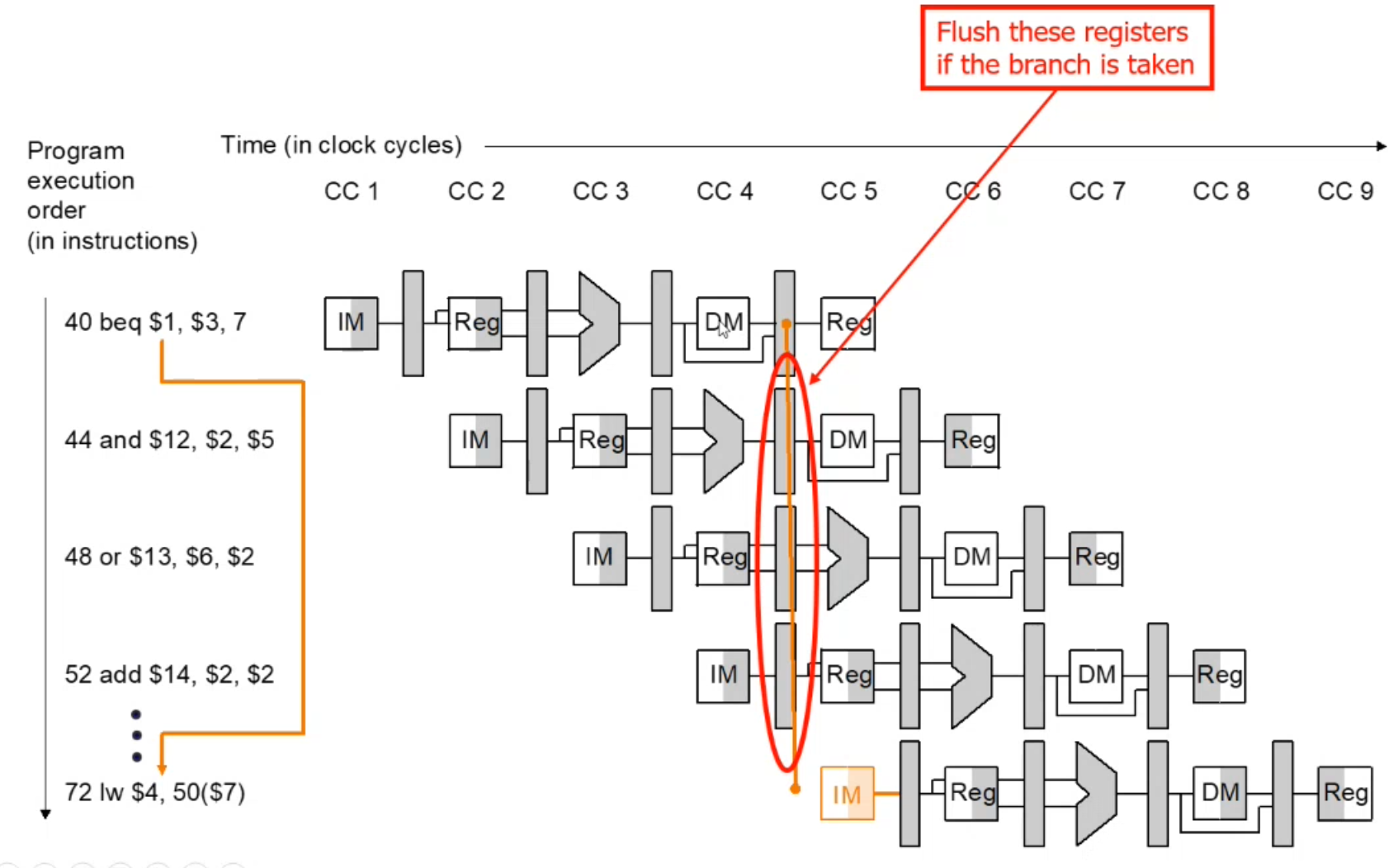
If the prediction is wrong, 3 instructions may need to be flushed. (Can be improved!)
To mitigate the performance penalty from flushing, there are several improvement methods.
- Make the decision for branching earlier
- Calculate the target address in the ID stage
- Compare register contents in the ID stage (using bitwise XOR)
- Require forwarding to ID stage and hazard detection
- (Only if the branch is dependent upon the result of an R-type or LOAD instruction that is still in the pipeline)
- Flush only one instruction
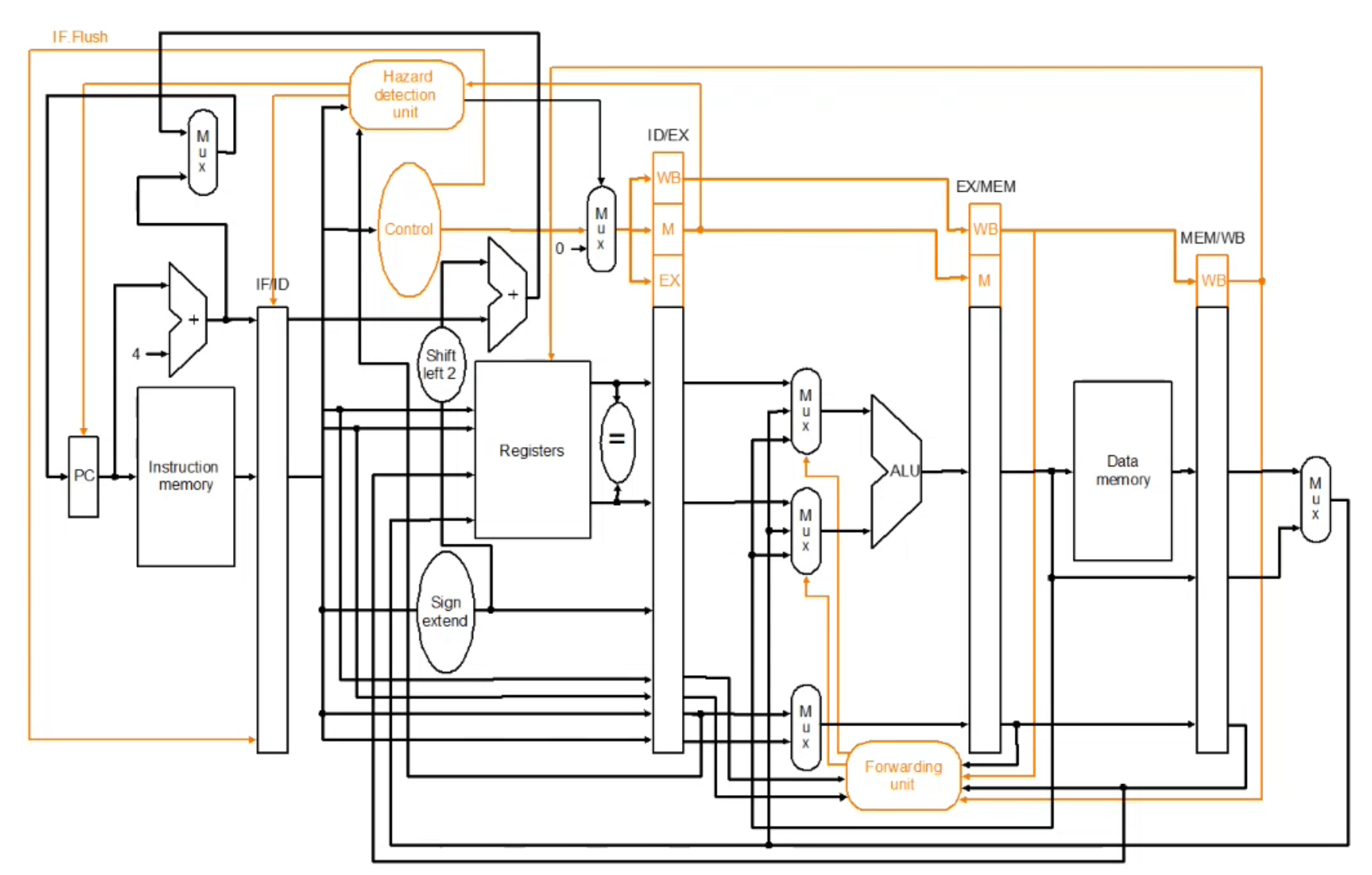
IF.Flushcontrol signal sets the instruction field of the IF/ID register to 0
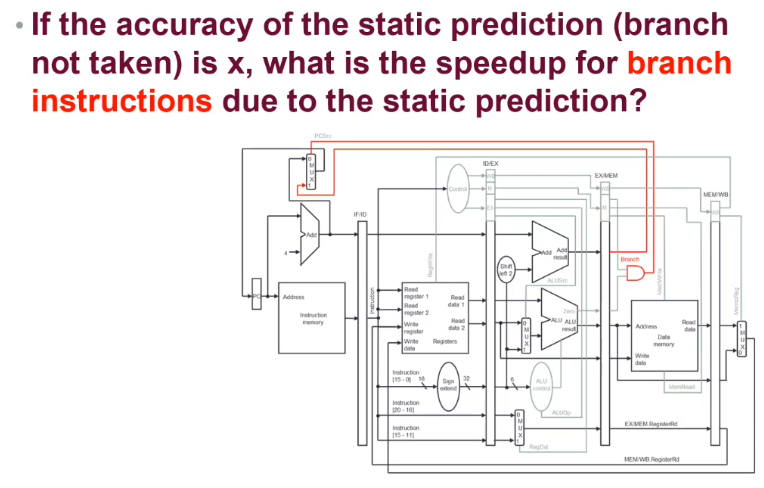
4N / (xN * 1 + (1-x)N * 4)
4/(4-3x)
Dynamic Prediction
Prediction is made on the fly, depending on the history of the branch behaviour.
This history is stored in a branch history table / branch prediction table.
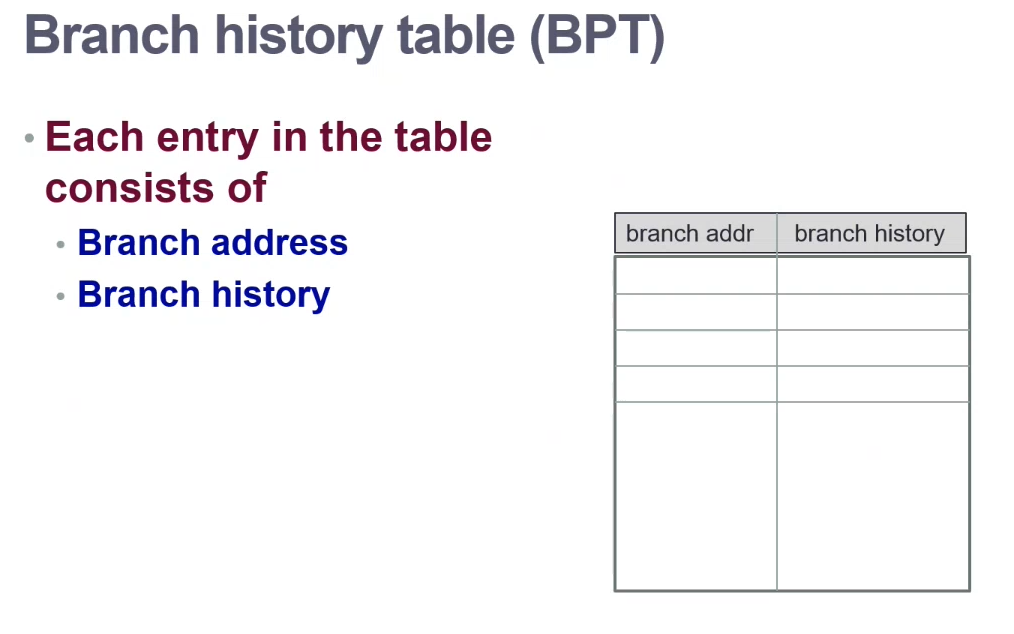
1-bit Prediction Scheme
The history bit (1-bit wide), contains the result of the branch - either taken or not taken
Simple, however it has limited prediction accuracy.
i.e in a loop, the final case will exit the loop. If that loop is re-executed, the exit check history will be incorrect for the future iterations
- T -> T
- N -> N
2-bit Prediction Scheme
The history bit is now 2 bits wide. A prediction must be wrong twice before it is changed
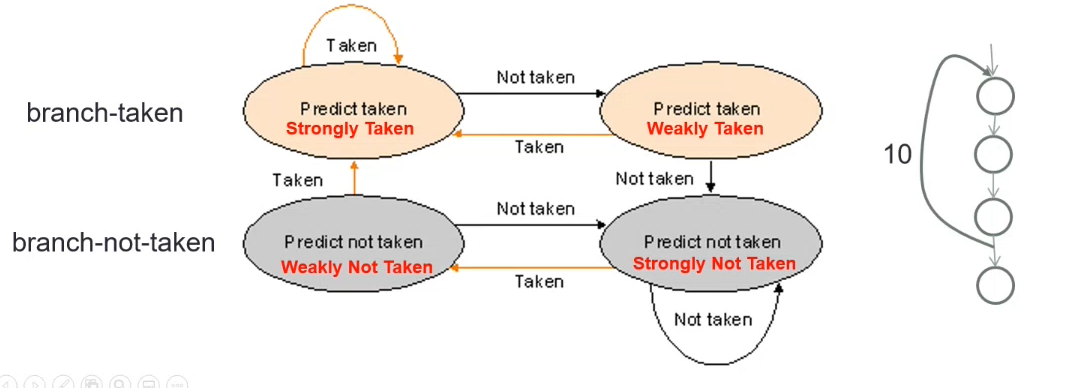
- TT -> T
- NN ->
- TN -> T
- NT -> N

n-bit Prediction Scheme
- Frequency based - (majority -> prediction) - no correlations are taken into account
- Pattern based (more accurate and efficient)
- Branch history shift buffer - correlation oriented
- Pattern prediction history table - frequency oriented
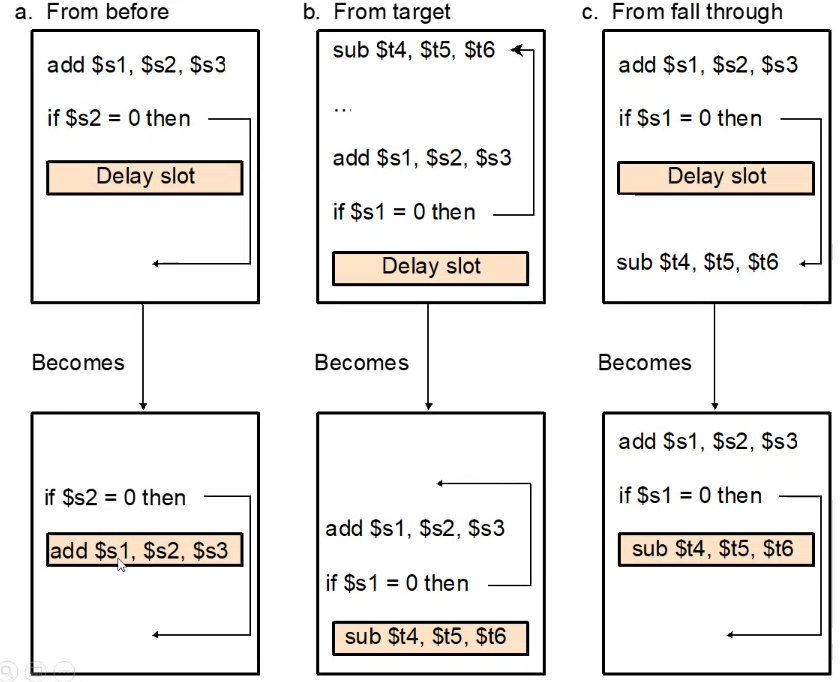
Delay Branch
A compiler-oriented approach that will always execute the instruction after the branch