Multiprocessors
Contents
Why

Increasing CPU frequency helps to increase performance
Power Consumption
Power = Capacitive Load * Voltage² * Frequency
Reducing load, voltage and frequency can decrease power consumption
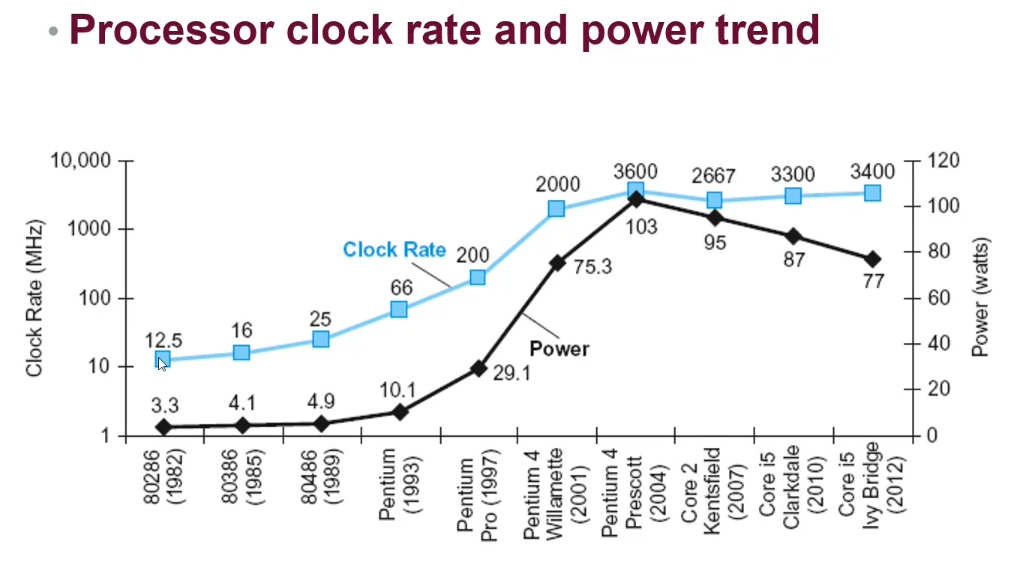
CPU frequency has hit a "frequency wall" / "power wall" - hard to get faster. Instead of increasing the speed of a core, just add more cores!
Multiprocessors
All processors perform in parallel, achieving high performance.
Power consumption scales linearly.
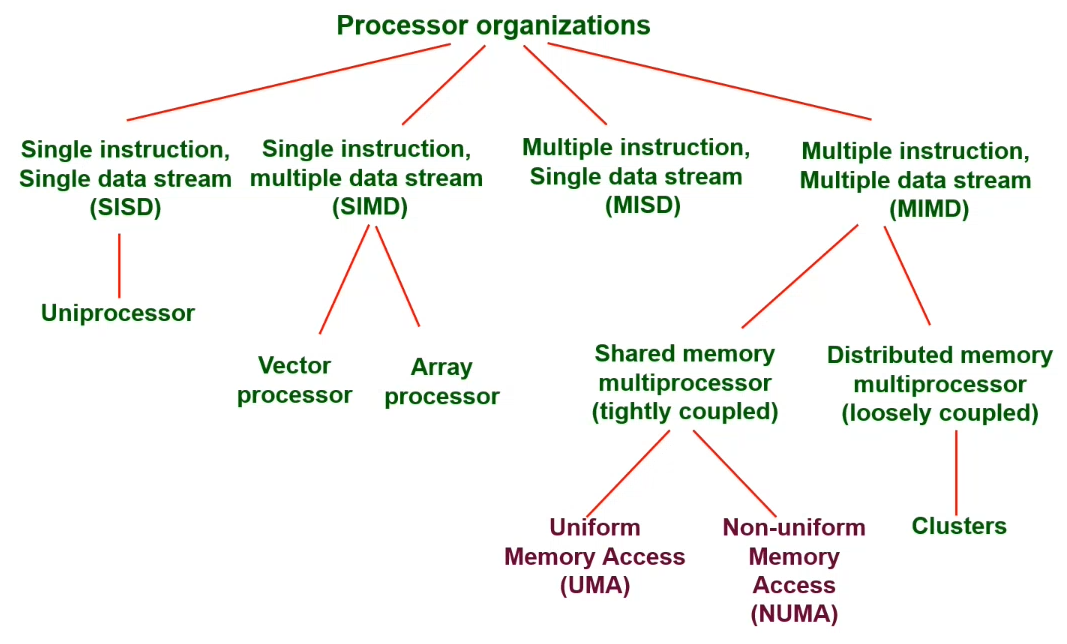
Processor Classes
- SISD - Single instruction, single data
- SIMD - Single instruction, multiple data
- MISD - Multiple instruction, single data
- MIMD - Multiple instruction, multiple data
UMA (Uniform Memory Access)
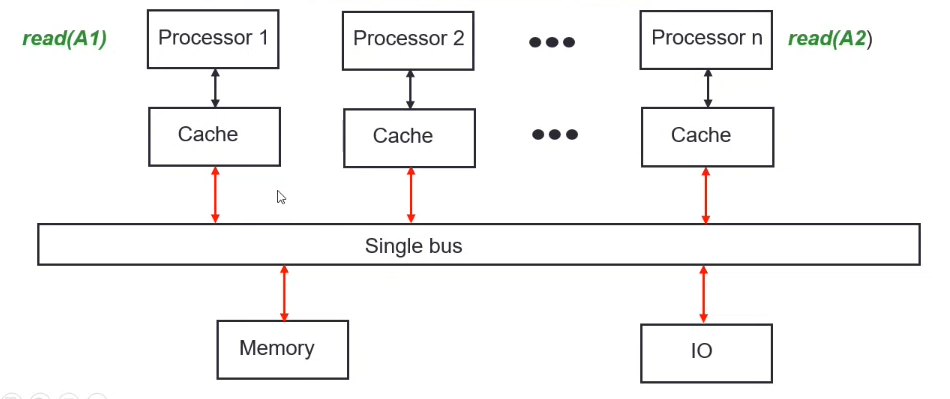
All processors share a single bus to access memory and I/O resources.
Allows for simple data sharing, but restricts performance (exclusive access).
All memory locations have similar latencies - hence the uniform access.
Each processor also has a local cache (which will be invalidated when memory updates??? * cache coherence *)
NUMA (Non-Uniform Memory Access)
Memory-connected Multiprocessors
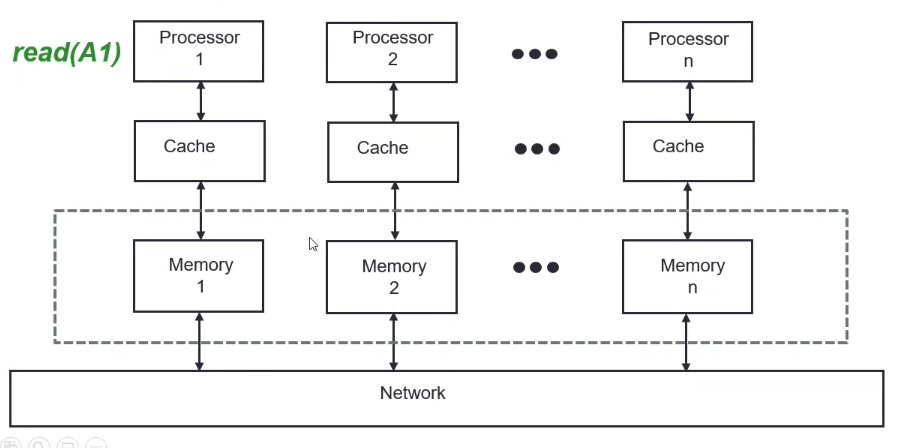
Each processor has their own local memory, which is accessible to other processors over a network / bus
Cache Coherence
Shared-memory multiprocessors have cache coherence problems - copies of the same data need to be updated in all locations. This can be performed in different ways
- Software Implementation
- During compilation, the compiler identifies data items that may cause cache inconsistency, and disables the cache-ability of those items.
- Hardware Implementation
- Snoop-based Protocol (for UMA)
- Write-update - Update other caches
- Write-invalidate - Mark data on other caches as invalid
- Directory-based Protocol (for NUMA)
- Snoop-based Protocol (for UMA)
MESI - Write-Invalid | Snoop
Uses four states in the cache line
- Modified - Data modified, data in specific cache
- Exclusive - Data same, data only in the current cache
- Shared - Data same, data in other caches
- Invalid - Data invalid
EG: Read Miss
Processor 1 wants to access data that is only cached in processor 2
Processor 1 checks it cache (miss), then sends a read miss into the bus.
Processor 2 changes its state from Exclusive to Shared
Data is loaded from memory
Processor 1 wants to access data that is cached by multiple processors
Processor 1 checks it cache (miss), then sends a read miss into the bus.
The processors that contain the data change their state from Exclusive to Shared
Data is loaded from memory
Processor 1 wants to access data that has been cached AND modified by another processor 2
Processor 1 checks it cache (miss), then sends a read miss into the bus.
Processor 2 sends an alert
(Processor 1 waits)
Processor 2 writes the updated value into the memory
Data is loaded from memory
EG: Read Hit
No state change, data is just read
EG: Write Miss
Send RWITM signal (Read With Intent To Modify)
When the line is loaded, it is immediately marked as modified (even before the modification)
Write Policy: fetch-on-write
Some other cache has a modified copy
The cache tells the processor that another processor has a copy of the modified data
Processor surrenders the bus and waits
Other processor access the bus and writes the modified data to main memory
The other processor marks the cache line as invalid
The processor then tries again
No other cache has a modified copy
Other caches invalidate its own copy
As usual
EG: Write Hit
Shared
Other caches will modify their state to invalid
Exlusive
No control signal needs to be sent along the bus
Modified
No control signal needs to be sent along the bus.
Note: Other processors will already have their cache line marked as invalid
Issues with Snooping
Scalability.
A single bus and shared memory prevents processors from simultaneously accessing memory. In addition, each processor block needs to be queried for every operation.
Directory Based Protocol (for NUMA)
Processors send signals directly to related processors to keep caches up to date.
Uses a directory to keep track of the memory block status
Each processor has its own directory, which contains entries.
Each entry contains a dirty bit, and a presence vector (length n, n is the number of processors)
Each address has a 'home directory', given by the value of its address


Memory Consistency
The order between accesses to different memory locations is very important.
Memory consistency models provide rules that applications follow to work together.
Sequential Consistency (SQ)
The result of any execution is the same as if the operations of all of the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program - Lamport 1979
- Overall memory access is serialised
- Each processor follows the same order as specified by its program
- Writes should also be atomic operations
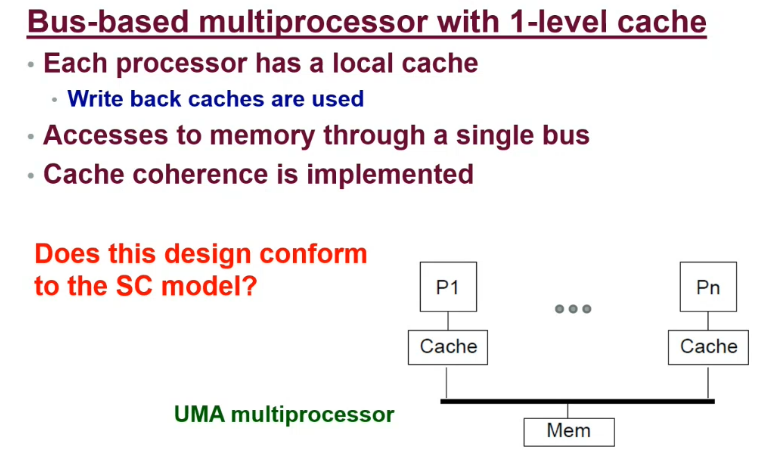
- Memory access is serialised
- Uses a bus, so only one memory address is accessed at a time
- Cache coherence is observed
- Writes are atomic
- Access from a single processor complete in program order
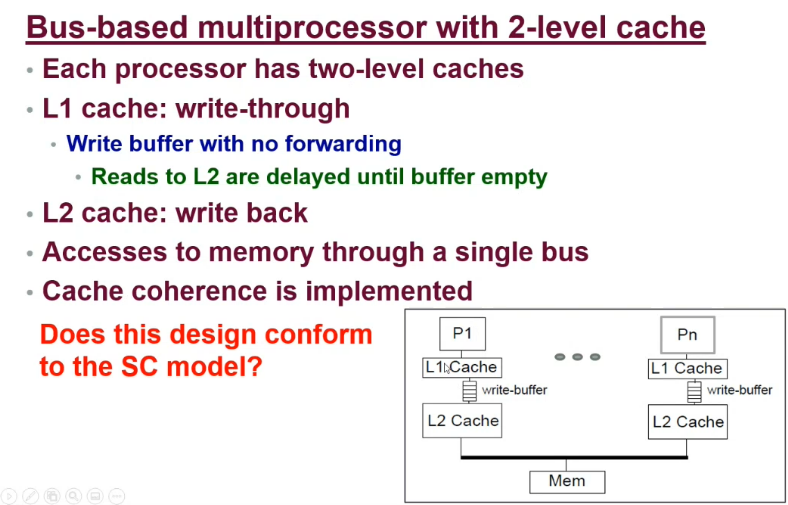
- If access never hits the L1 cache, then the system behaves.
- If the L1 has a read hit, completion of accesses can be out of order
- A write operation may take longer than a subsequent request to read data that is cached.
- To maintain sequential consistency, access to the L1 cache needs to be delayed until there are no pending writes in the buffer
- Nullifies the benefits of a write buffer.

Access in issued order do not necessarily get completed in order due to the distribution of memory and varied-length paths in the network
Writes are inherently non-atomic as new values will be visible to certain processors whilst still been seen as the old version in others
To maintain sequential consistency
- Need to know when a write completes
- For providing atomicity, delay further instructions to the longest operation
- Require acknowledgement messages
- Wait for all invalidation requests to be acknowledged
- Ensure write atomicity
- Delay access to the new value until all acknowledgements are received
- Ensure order form a processor
- Delay access until the previous one completes
Sequential consistency severely restricts hardware and compiler optimisations, and it does not fully guarantee the single execution result.
- Need to know when a write completes
Instead.... do it as software!
Programmer Model
Contract between the programmer and the system
- Programmer provides synchronised programs
- System provides sequential consistency at a higher performance
The programmer explicitly labels synchronised parts of the program - and data accesses are ordered through synchronisation
Synchronised (parallel) programs can be generated automatically through the compiler, and can also be explicitly created through easily identified synchronisation constructs. The programmer is responsible for guaranteeing the correct order of data access