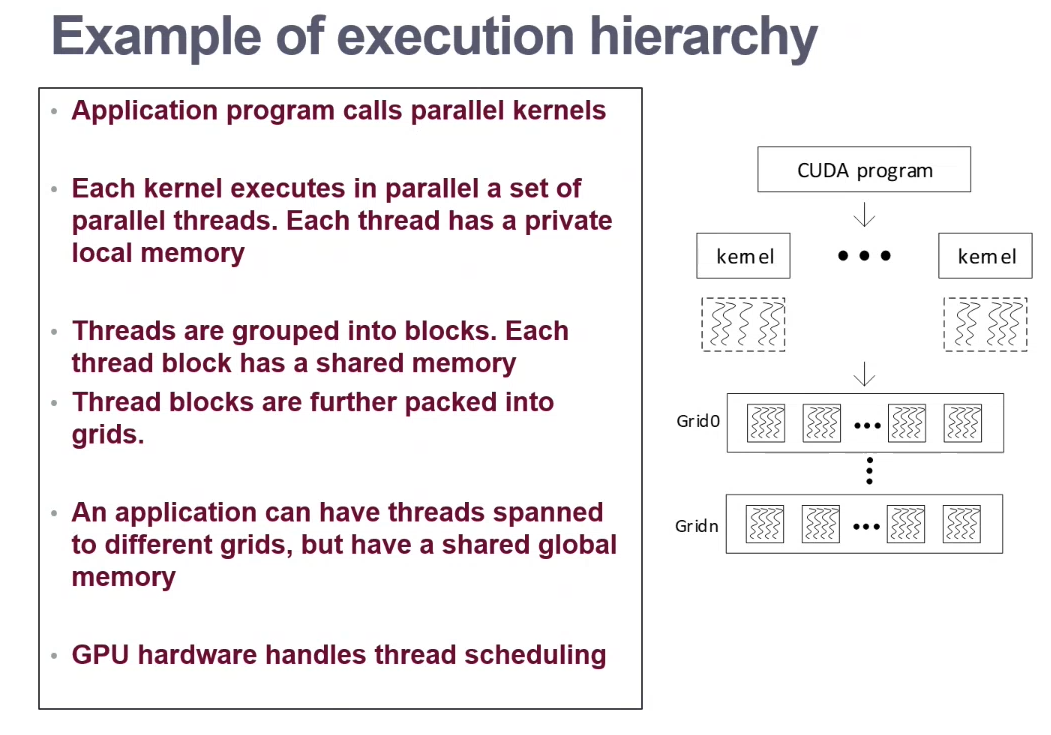
More Hardware Designs on Parallel Processing
Contents
Improving Performance
Parallelism
- Widen the basic word length of the machine
- 8 bit
- 16 bit
- 32 bit
- 64 bit
- Vector execution
- Execute a single instruction on multiple pieces of data
- Parallel-ise instructions
Instruction-level Pipelining
Deep Pipeline
The depth of the pipeline is increased to achieve higher clock frequencies (more stages).
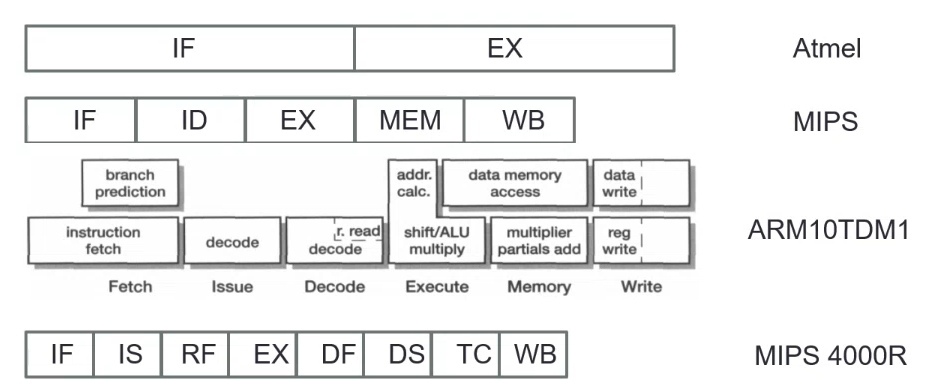
Limitations
- Stage delay cannot be arbitrarily reduced
- There is a delay for each register pipeline required
- Pipeline flush penalty will discard more instruction
- Memory hierarchy can stall executions
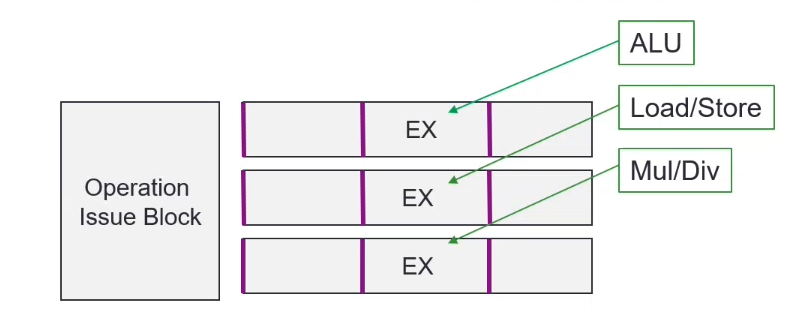
CPU with Parallel Processing
Multiple execution components can be performed simultaneously by having parallel groups of instructions
(Software) VLIW Architecture
VLIW - Very Long Instruction Word

- Issues with more instructions in parallel
- May create more data hazards
- Forwarding in the pipelined datapath becomes hard
- Identifying parallel instructions is not easy
- More aggressive scheduling is required
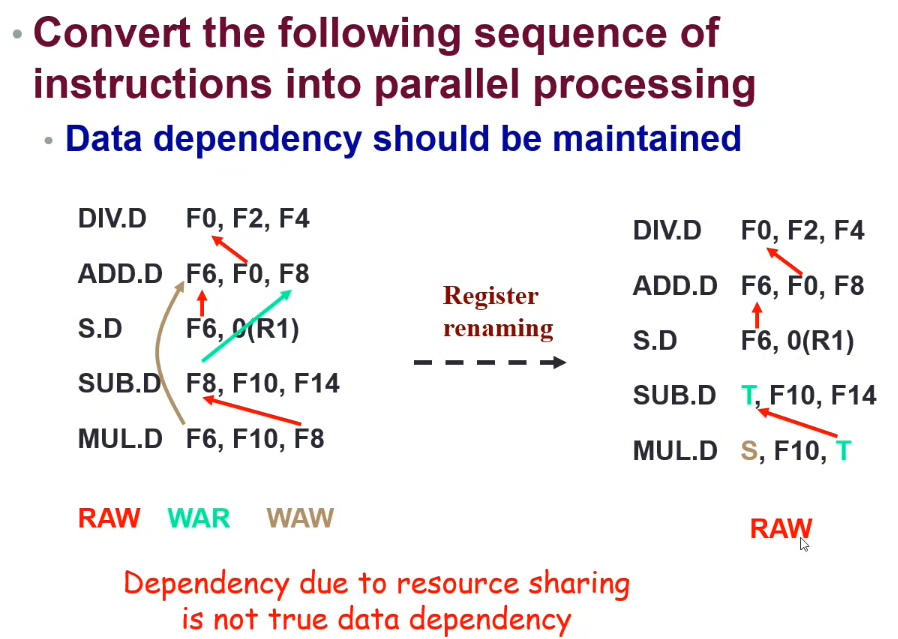
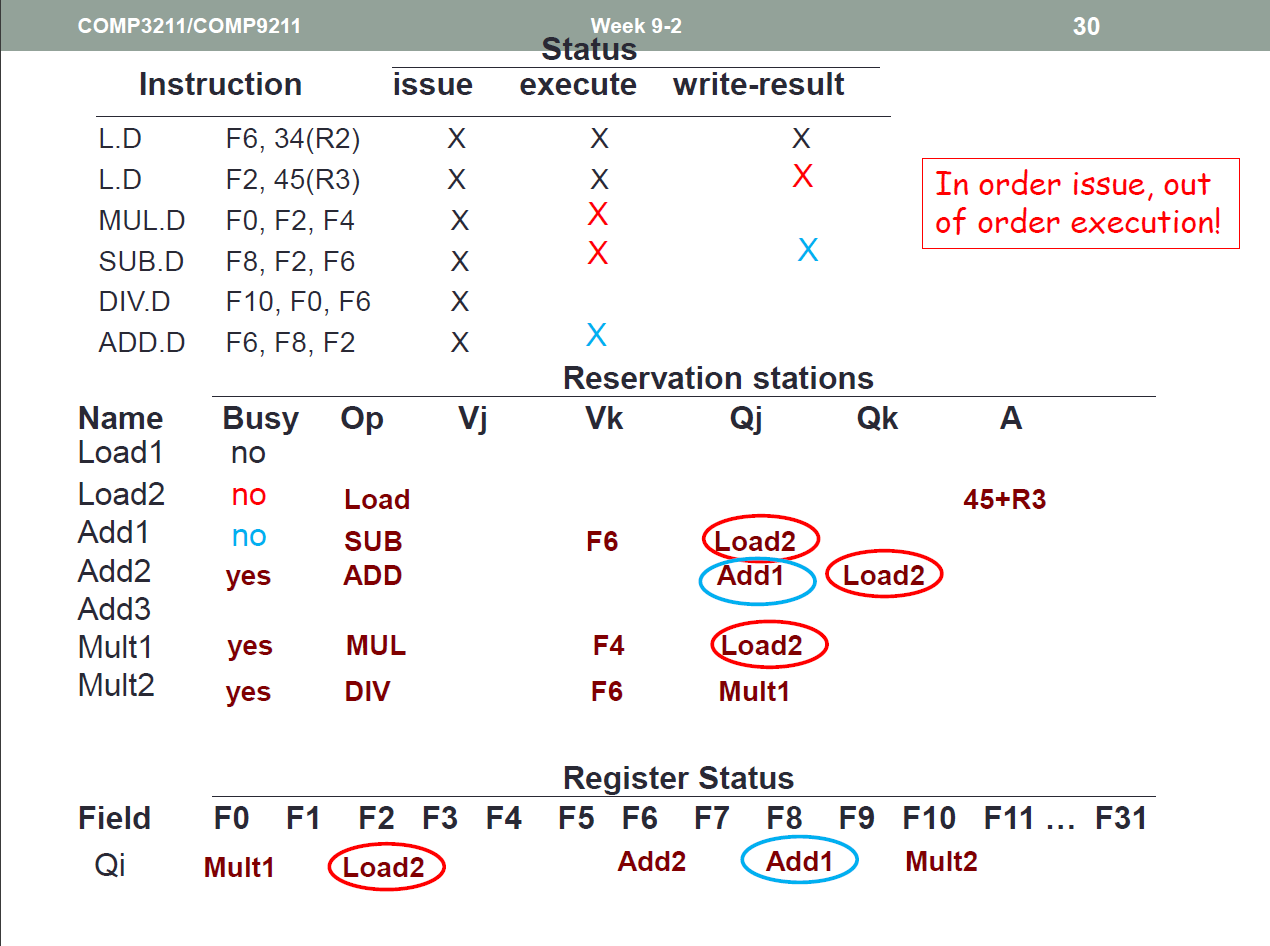
Above: The SUB.D instruction does not use the previous F8 register value. To increase performance, we could change the register used for SUB.D - which allows the instructions to be run in parallel as they no longer have a data dependency.

(Hardware) Superscalar Architecture
Dynamic Scheduling
TL;DR - Each execution unit has its own queue
The hardware issue component in the processor schedules instructions to different parallel execution units
- Track instruction dependencies to allow instruction execution as soon as all operands are available
- Renaming registers to avoid WAR and WAW hazards
Issue
- Get next instruction from the queue
- Issue the instruction and related available operands from the register file to a matching reservation station entry if available, else stall
Execute
- Execute ready instructions in the reservation stations
- Monitor the CDB (Common data bus) for the operands of not-ready instructions
- Execution unit idles until a ready instruction is available
Write Result
- Results from the EU are sent through the CDB to destinations
- Reservation station
- Memory load buffers
- Register file
- The write operations to the destinations should be controlled to avoid data hazards
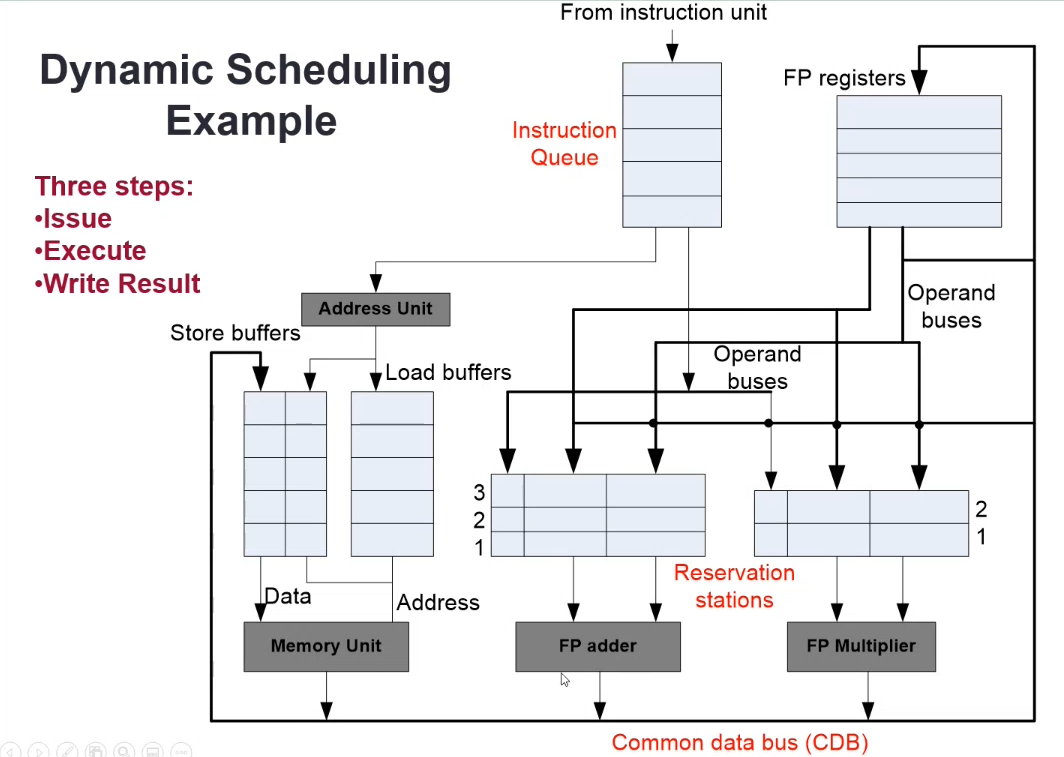
Special data structures in the register file, reservation stations and memory buffers are used to detect and eliminate hazards
Reservation Station


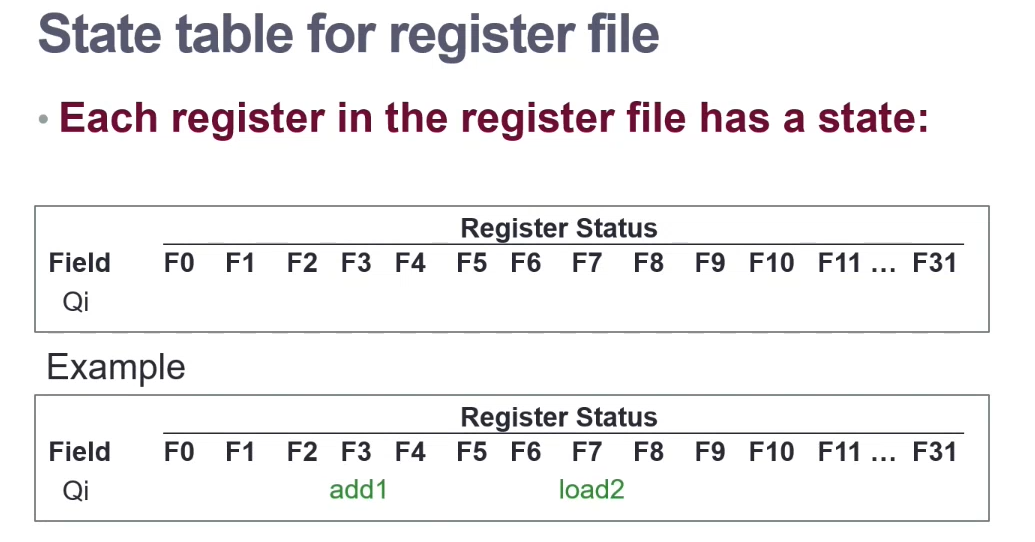
The state table holds the a link to the execution unit index that is using the register
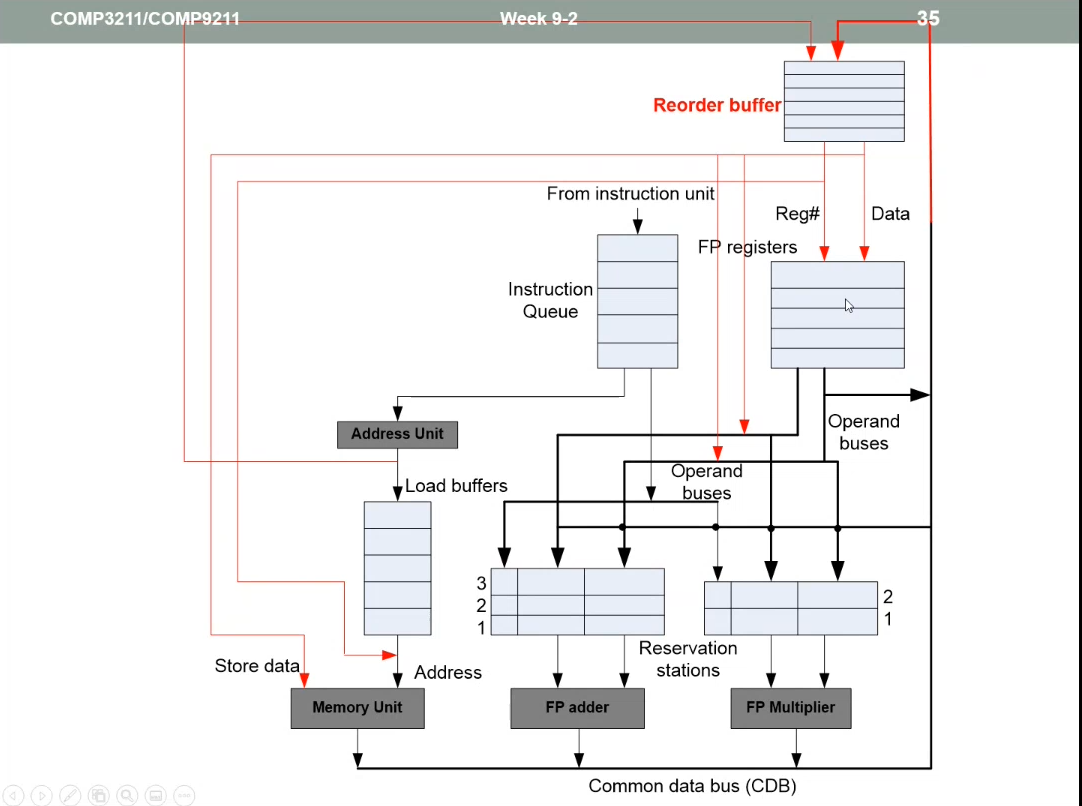
Dynamic Execution with Speculation
- Issue, Execute, Write Result, and COMMIT
The commit step allows instructions to execute out of order, but force them to commit in the correct execution order

Thread Level
Multithreaded Processors
When one thread is not available due to an operation delay (i.e. memory access taking a long time), the processor can switch to another thread
Hardware level multithreading
Thread switching has less overhead than context-switching
- Fast switching between threads
- Requires extra resources: replicated registers, PC, etc
Fine-grained Multithreading
Round-robin approach
- Switch threads after each cycle
- If one thread stalls, another is executed
Coarse-grained Multithreading
- Only switch threads on long stalls (i.e. L2-cache miss)
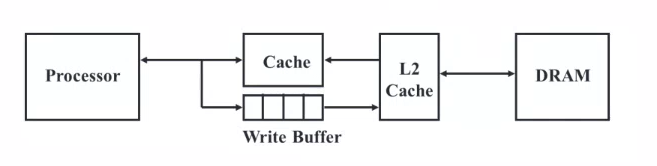
Simultaneous Multithreading (SMT)
- A variation of HW multithreading that uses the resources of superscalar architecture
- Exploits both instruction-level parallelism and thread-level parallelism

System Level - GPUs
Graphics Processing Units are processors developed for processing lots of data at once (i.e. all the pixels on a screen)
Typical Tasks
- HSR - Hidden Surface Removal (Remove hidden parts of a 3D object to be shown on a [2D] screen)
- Shading - Making a flat object look more 3D-like
- Texture Mapping - Providing high frequency details, surface texture, colour information
Many tasks require a huge level of parallelism, however it is common that all tasks are independent (do not rely on each other)
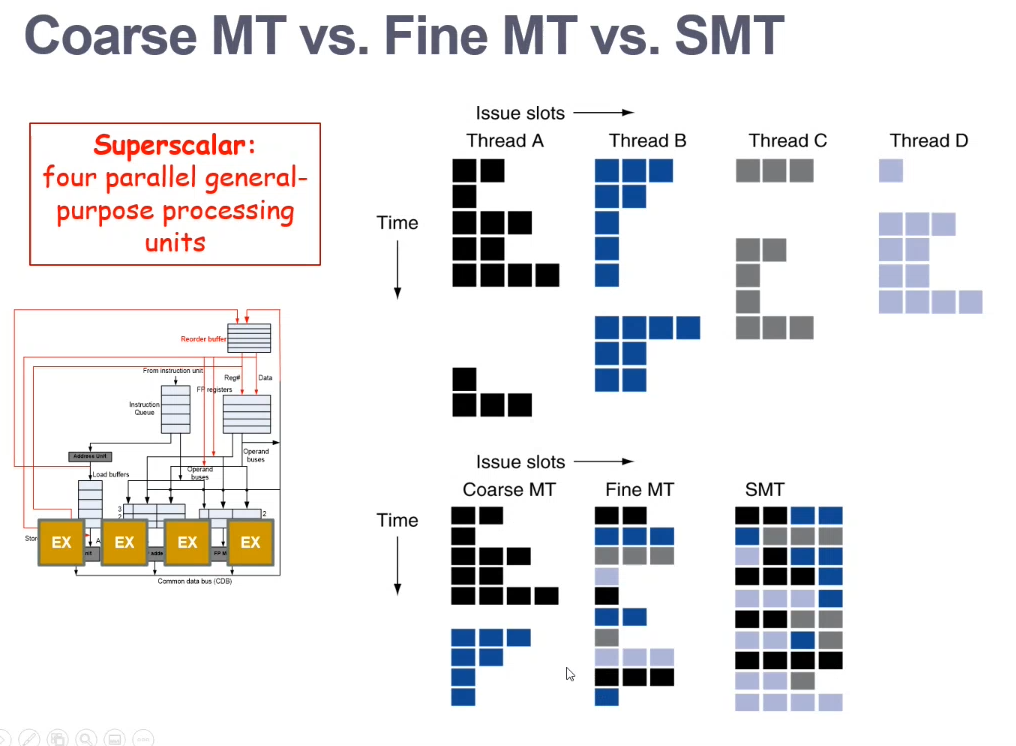
Example: Powerful but single threaded
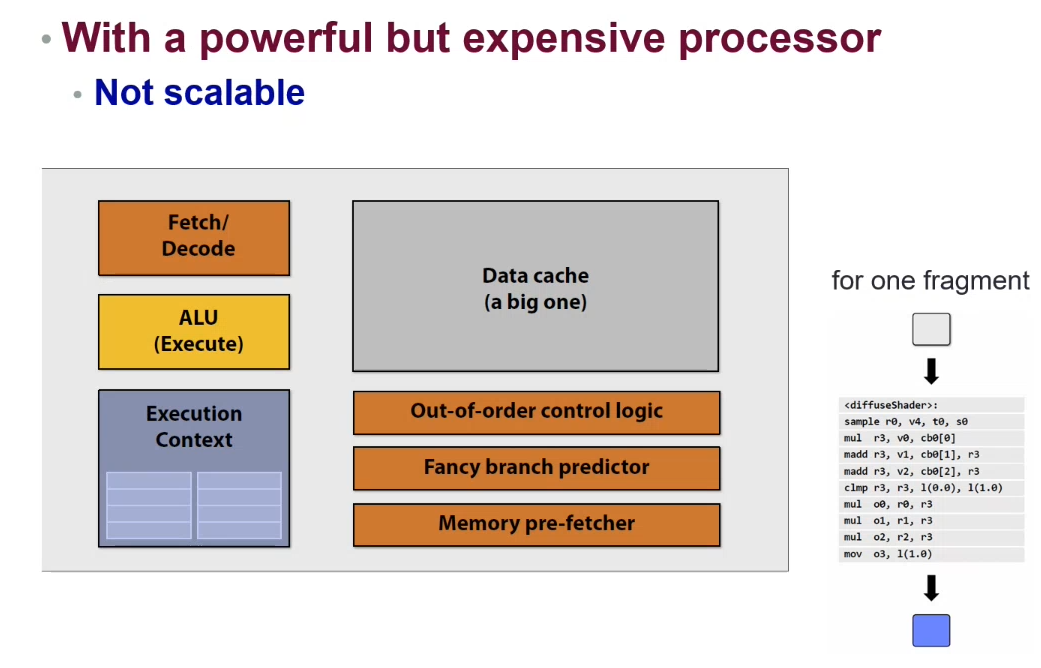
Example: Cheap but multiple processors
BRRRR
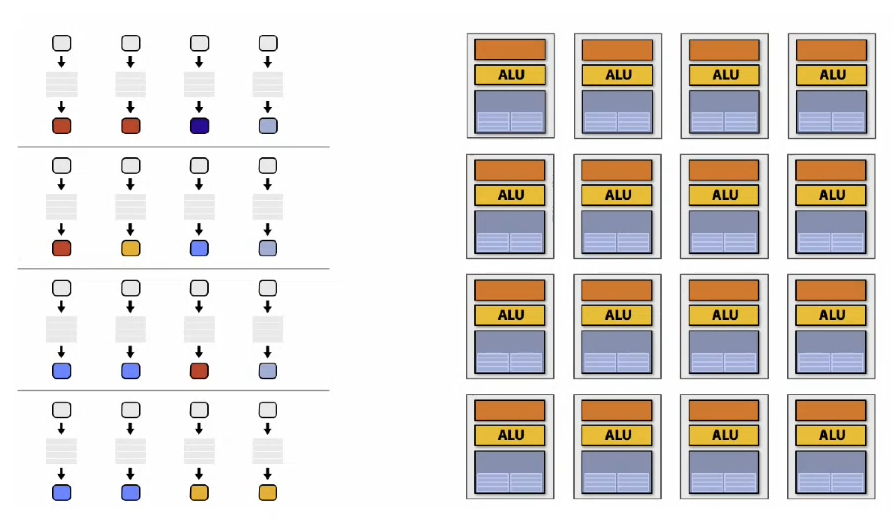
SIMD
Since multiple processors are performing the same instruction, just on different data fragments, the instructions can be shared (same fetcher/decoder).
Each execution unit has its own local memory, and they all share a larger memory
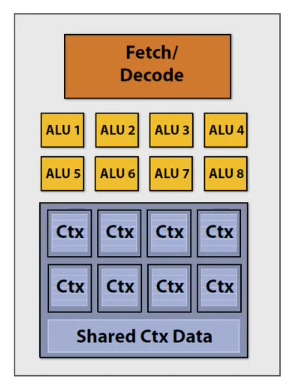
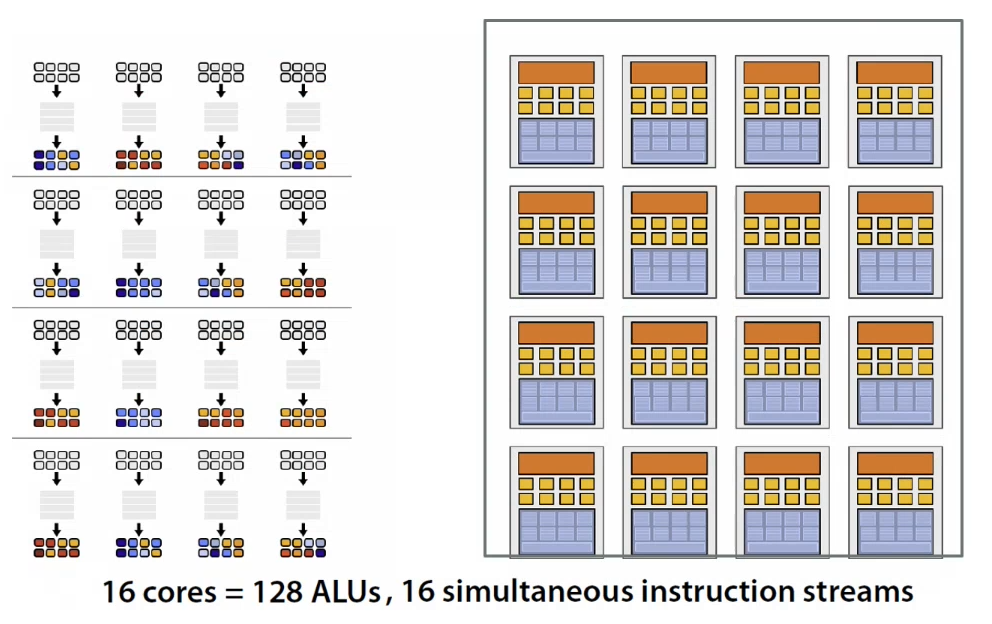
In the event that there is a stall (i.e. data not available), then the processors can thread-switch to another thread for continued execution
Remarks
- Use many cheap cores and run them in parallel
- Easier than improving a single core by
ntimes
- Easier than improving a single core by
- Pack cores full of ALUs and share instruction streams across groups of data sets
- i.e. SIMD vector
- Avoid long stalls by interleaving execution of many threads
Note: CUDA
CUDA (Compute Unified Device Architecture) is NVIDIA's platform to use their GPUs for arbitrary operations that require parallel computation.
It is executed with some C-like programming language, and unifies all forms of GPU parallelism as a CUDA thread.